これまでの災害で明らかになった数々の課題や教訓。決して忘れることなく、次の災害に生かさなければ「命を守る」ことができません。防災・減災につながる重要な情報が詰まった読み物です。
34テラバイトのデータと格闘して「全国ハザードマップ」を公開した理由

5月下旬に公開を開始したNHKの「全国ハザードマップ」。川の氾濫による洪水リスクを中心に掲載し、多くの方に活用頂いています。⇒「NHK全国ハザードマップ」の紹介記事はこちら一方で、「市町村が出しているハザードマップがあれば十分だ」「リスクを網羅していない不完全なマップの公開は良くない」「NHKではなく国が取り組むべき仕事ではないか」といった意見も頂きました。今回なぜ、このような取り組みを行ったのか。どうやってデータを収集して地図を作ったのか。詳しく説明します。
2022年のNHKスペシャルなどで紹介された内容です
目次
なぜ「デジタルデータ」を集めたのか?
私たちはこれまで「ハザードマップを見て下さい」という呼びかけを、テレビやラジオのニュースや番組、ネット記事、SNSなどで繰り返してきました。
なぜなら、自分の暮らす場所のリスクを知ることが、災害から命を守るスタートだからです。そしてハザードマップは、一番簡単にリスクを確認できるツールです。
現在、ハザードマップは市区町村が紙に印刷して住民に配布するのが一般的です。あわせて市区町村のホームページにPDFが掲載されていることが多いです。
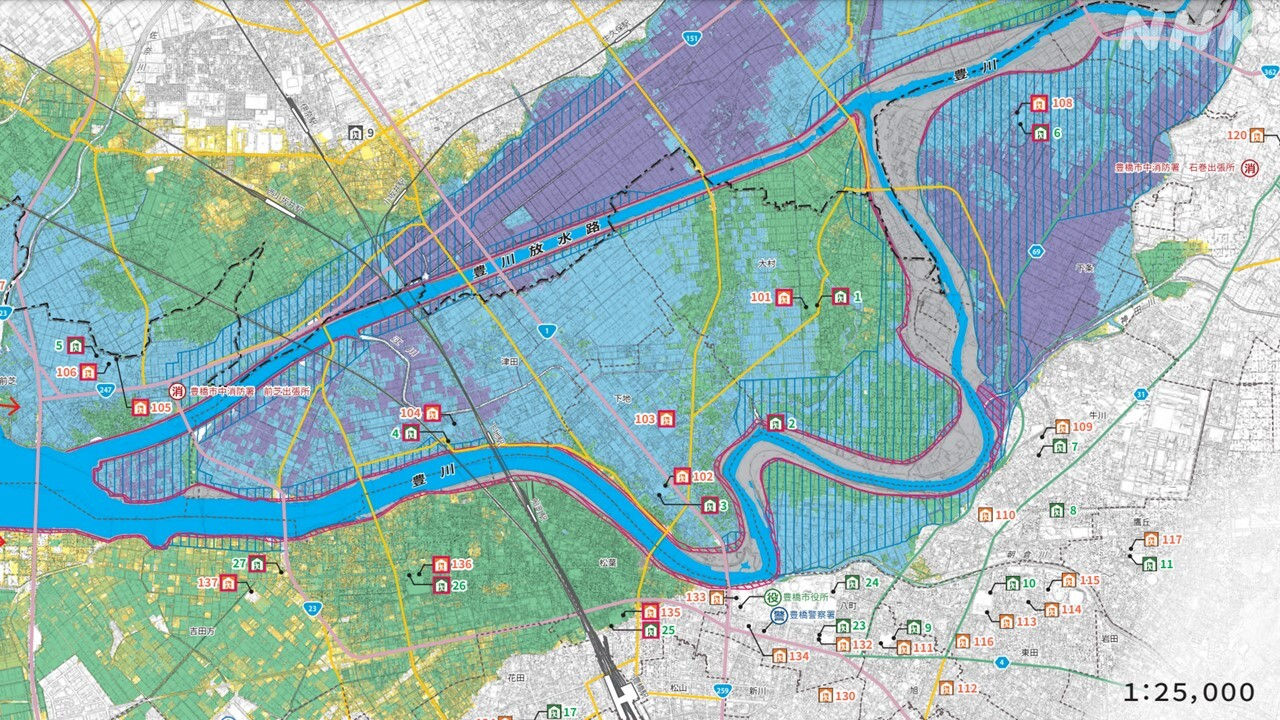
最も良いのはそれを確認することです。ただ、紙やPDFで自宅や職場を探すのは結構面倒です。小さなPDFをPC画面で拡大し「ここかな?こっちかな?」と調べるのは思っているより根気が必要です。
そもそも該当するハザードマップを探すこと自体に苦労することもあります。
市区町村の中には「○○市○○地区」とか「○○市北部」などと地域を細かく切り分けてPDFを公開しているところもあります。お住まいの方にとっては便利ですが、観光客や土地勘が無い人は、どれが確認したいハザードマップなのか判断できず順番に開いていく…という事態が発生します。
また、自治体ごとに紙やPDFで公表している現状では、「職場がある隣の市のリスクを確認したい」「他県にある実家のリスクを調べたい」と思うと、その自治体のホームページにアクセスし直して、再びハザードマップを探さなければなりません。
こうした問題はデジタルデータを活用した地図であれば解決します。
住所や目印になる施設を検索して表示することができるので、見たい場所にすぐにたどり着けるからです。市町村や都道府県の境界も関係なくリスクが表示できるので、何度も検索する必要はありません。つまり、「リスクを確認する手間」を大幅に省くことができるのです。
この「手間を省く」というのは「便利になる」ということにとどまらない、とても大事なことだと考えています。例えば、大雨のニュースを見て「ちょっと自宅のリスクを確認してみようかな」と思っても、なかなかハザードマップにたどりつけない、たどりついても自宅がどこか探すのに時間がかかる…となると、途中で「まぁいいや」と諦めてしまうかもしれません。
さらに、デジタルデータにすることで、単純に閲覧するだけではなく、分析にも使えるというメリットがあります。紙やPDFでは分析できませんが、デジタルデータであれば、国勢調査の人口データや建物の位置データと重ね合わせることで、災害リスクに関するリスクを分析することもできます。犠牲になった方が被害にあった場所を分析すれば、次の災害に生かすべき教訓も見えてきます。
⇒「83人の死から見えたものは」※2020年7月豪雨災害の分析記事はこちら
毎年、水害が起きて犠牲者が出る中では、「誰でも」「どこでも」「簡単に」リスク情報にアクセスできる環境は無くてはならないもので、そのためにもデジタルデータは必須です。
なぜNHKでやる必要があったのか?
実はデジタルデータを使った地図として、国土交通省の「重ねるハザードマップ」というサイトが存在します(災害に詳しい方はご存じかと思います)。
「重ねるハザードマップ」は全国の洪水による浸水リスクをまとめて地図上に表示するサイトです。正確に言うと、大雨で洪水が起きた時の浸水範囲や深さを示す「浸水想定区域図」というデータを載せています。地図で浸水リスクのある場所をシームレスに確認できる上に、住所検索も可能です。私たちもよく使っています。
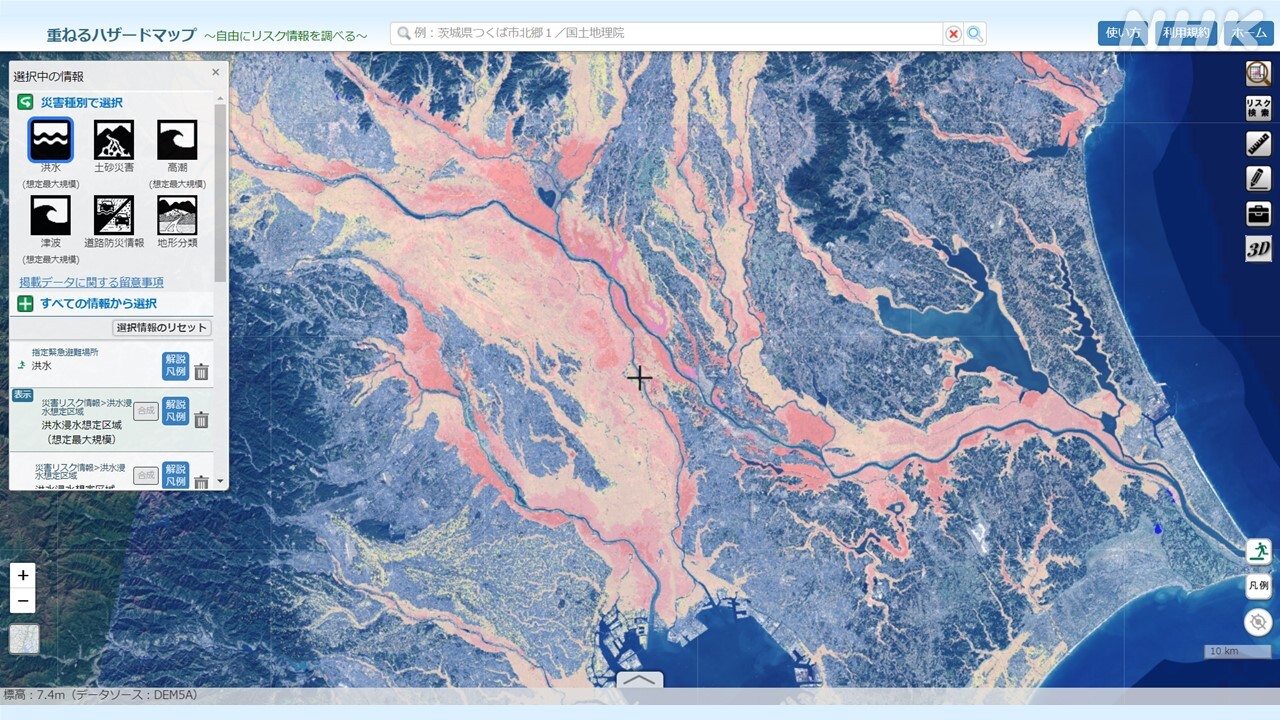
ただ、とても便利なサイトな一方で「掲載されている河川数が少ない」という課題がありました。
少し専門的な話になりますが、日本ではこれまで、水防法という法律で、比較的規模の大きな「洪水予報河川」と「水位周知河川」と呼ばれる川(※1)では、大雨で洪水が発生した場合をシミュレーションして浸水範囲や深さを計算し、「洪水浸水想定区域図」を作成して公表することを、河川を管理する国土交通省や都道府県に対して義務付けていました。日本にはこうした川が全国で約2200あります。
現在「重ねるハザードマップ」は基本的にこの約2200の河川を対象にしていますが、このプロジェクトを始めた去年(2021年)6月末時点で掲載されていたのは968河川。掲載率は43%あまりと、半分以上が掲載されていなかったのです(※2)。
では、なぜ掲載率が低かったのでしょうか?
先ほども説明しましたが、浸水リスクを示す「洪水浸水想定区域図」は、河川を管理する国土交通省や都道府県が作り、公表することが義務付けられています。ところが、その過程で作成されたデジタルデータをどう扱うかは、法律には規定がありません(※3)。
このため「重ねるハザードマップ」の掲載作業を行う国土地理院は、データを収集するところから始めなければなりません。国土交通省は毎年、洪水浸水想定区域のデジタルデータを提供するようにお願いする文書を都道府県に送っていますが、あくまで「お願いベース」。
最近は理解が広がってきているということですが、強制力がある訳ではないので、作成から時間が経過していてもデータが届かないケースもあるのです。

さらに、相次ぐ水害を受けて、国は去年(2021年)水防法を改正し、洪水浸水想定区域図を作成する河川を、従来よりも規模の小さな河川まで拡大することを決めました。これによって、今後、およそ15000河川で新たに洪水浸水想定区域図が出てくる見通しとなりました。
従来から洪水浸水想定区域図の作成が義務付けられている約2200の河川も掲載が完了しない中で、さらに掲載が必要な河川が増えていく。「このままでは追いつかない」と私たちは危機感を持ちました。
私たちはこれまで何度も被災地で取材をしてきましたが、その度に聞くのは「想定外だった」という言葉です。ただ、実際には事前にリスクが指摘されているケースが多いのも現実です。
例えば、2019年10月の台風19号(東日本台風)の犠牲者の7割近くは洪水ハザードマップなどで事前に危険性が指摘されている場所で被害にあっていました。
⇒「台風がくる!大切な命を守るために」※2019年台風19号の被害分析はこちら
一方で、NHKが昨年(2021年)実施した世論調査では、「ハザードマップを確認したことはない」と回答した人が3割に上りました。別のアンケート調査の中には半数以上が「確認していない」と回答したものもあり、まだまだ十分に使われているとは言えない状況です。
もちろんハザードマップは万能ではありません。リスクが指摘されていた場所の外側でも犠牲者は出ていますし、リスクは認識していても逃げることができなかった方もいると思います。また、ハザードマップの整備が間に合っていない場所もあります。
現状ではどう頑張っても全てのリスクを網羅したマップを作ることはできませんが、それでも、公表されているリスク情報を1つでも多く集めることで助かる人を1人でも増やせないか。せっかくあるリスク情報を使い切ることで犠牲者を1人でも減らせないかと考えました。
残念ながら水害は待ってくれません。ですから国が掲載しきれないのであれば、NHKでやってみようと考えた訳です。そこで、まずは毎年犠牲者が出ている河川洪水についてのリスク情報を集め、誰でも、どこでも、簡単に確認できるようにしたいと考え、プロジェクトをスタートさせました。
このプロジェクトにはもう1つ大事な目的がありました。
それはデジタルデータの課題を検証することです。以前、取材である県に洪水浸水想定区域図のデジタルデータの提供を依頼したところ「PDFしか手元にありません」と言われたことがありました(このときはPDFと地図を重ね合わせて何とか浸水範囲を描画しました)。「PDFを公開しているのに、もととなるデータが無いなんてことがあるのか」と疑問に思っていました。
国土交通省「重ねるハザードマップ」の掲載が進まない理由を取材している時には「データの確認に時間がかかる」という話も聞きました。自治体からデータの提供されても、担当者と内容について何度も確認し、場合によっては修正するため、掲載までに1年以上かかるケースもあるということでした。
こうした経験から、浸水想定区域のデータの扱いに課題があり、一元的な管理や広く活用するための環境整備が進んでいないのではないかと感じていました。それも今回のプロジェクトで実際にデータを収集することで実態が見えると考えました。
----------
(※1)洪水予報河川:川の水位の状況や今後の見込み(洪水予報)が発表される川。氾濫すると重大な被害が出るおそれがある流域面積が大きい川が指定される。水位周知河川:川の水位の状況が発表される川。氾濫すると重大な被害が出るおそれがある川のうち、流域面積が小さく洪水予報を行う時間的余裕が無い河川が指定される。
(※2)国土地理院は「重ねるハザードマップ」に掲載している洪水予報河川と水位周知河川の数は2022年5月末の時点で1770河川と公表しています。この1年間で約800河川増えたことになります。掲載率は81%あまりまで上昇しましたが、約400河川が未掲載の状態です。また、国土交通省の「国土数値情報」も浸水想定区域図のデータを提供していますが、基本的には「重ねるハザードマップ」に掲載されているデータを扱っているため、やはり十分ではありません。都道府県の中には独自にデジタルデータを公開しているケースもありますが、これも県境をまたぐと表示がされない点に課題があります。
(※3)国土交通省は「浸水想定区域図データ電子化ガイドライン」を2006年に初めて作成し、電子データのフォーマット、ファイル形式などの統一化を目指している。
全国の「浸水想定区域図」に狙い
ここからは具体的にどのような作業をしていったのか説明します。
まず、最初に検討したのは「何のデータを収集するか」です。
そもそもハザードマップは、下の図のようなフローで作られて住民に届きます。

最初に河川を管理する国や都道府県が、大雨で洪水が発生した時の浸水範囲や深さを示す「洪水浸水想定区域図」を作成。多くの場合、自治体から委託を受けたコンサルタント会社がシミュレーションを実施します。
完成した「浸水想定区域図」は、河川を管理する国や都道府県が公開し、流域の市区町村にも提供します。提供を受けた市区町村は、それをもとにハザードマップを作成して住民に配布します。
最終形がハザードマップになっているわけですから、まずはハザードマップに記載されている情報をデジタルデータで取得することを考えました。全国およそ1800の自治体に電話をかけて提供をお願いすることにしました。
ところが、取材を進めると、ハザードマップに記載している情報や粒度は市区町村によって大きく異なり、1つのシームレスな地図の上に掲載するのが難しいことが見えてきました。
例えば、過去の浸水実績を記載しているところもあれば、無いところもあります。仮に記載していても「範囲」を示す自治体や、「地点」を示す自治体など、記載の仕方は分かれます。
一方で、今後大雨が降った時にどれくらい浸水するリスクがあるかを示す「洪水浸水想定区域図」は、国土交通省や都道府県から提供されたデータをほぼそのまま使っていることも見えてきました。浸水範囲や深さを算出するシミュレーションには時間もコストもかかるので、市区町村が別途、独自に実施することは稀で、ほとんどは国や都道府県から提供された浸水想定区域図を使っていたのです。
そこで、今回はハザードマップのもととなる「浸水想定区域図」を収集することを決めました。また、洪水浸水想定区域図には、100年~200年に1度の大雨による洪水を想定した「計画規模」と、1000年に1度の大雨による洪水を想定した「想定最大規模」の2種類がありますが、近年、各地で計画規模を上回る水害が起きていることから、「想定最大規模」を収集することを決めました。
今回は最終的に①洪水浸水想定区域図を地図に載せて多くの人に見てもらう、②他のデータと重ね合わせて分析に使う、ことを考えていたので、集めるのは「GISソフトで扱えるシェープ形式(※)の洪水浸水想定区域図(想定最大規模)」と決めました。
シェープ形式のデータは位置情報に加えて、シミュレーションに基づく「浸水深」の値を持っているため、どこでどのくらい浸水するかがわかるのです。
----------
(※)GISはGeographical Information Systemの略で「地理情報システム」を意味します。地図や地形データを扱うシステムです。シェープはGISで使われるファイル形式のひとつ。集まったデータは34テラバイト!
収集するデータが決まり、私たちが考えていた作業の工程はざっくり言うと次のようなものでした。
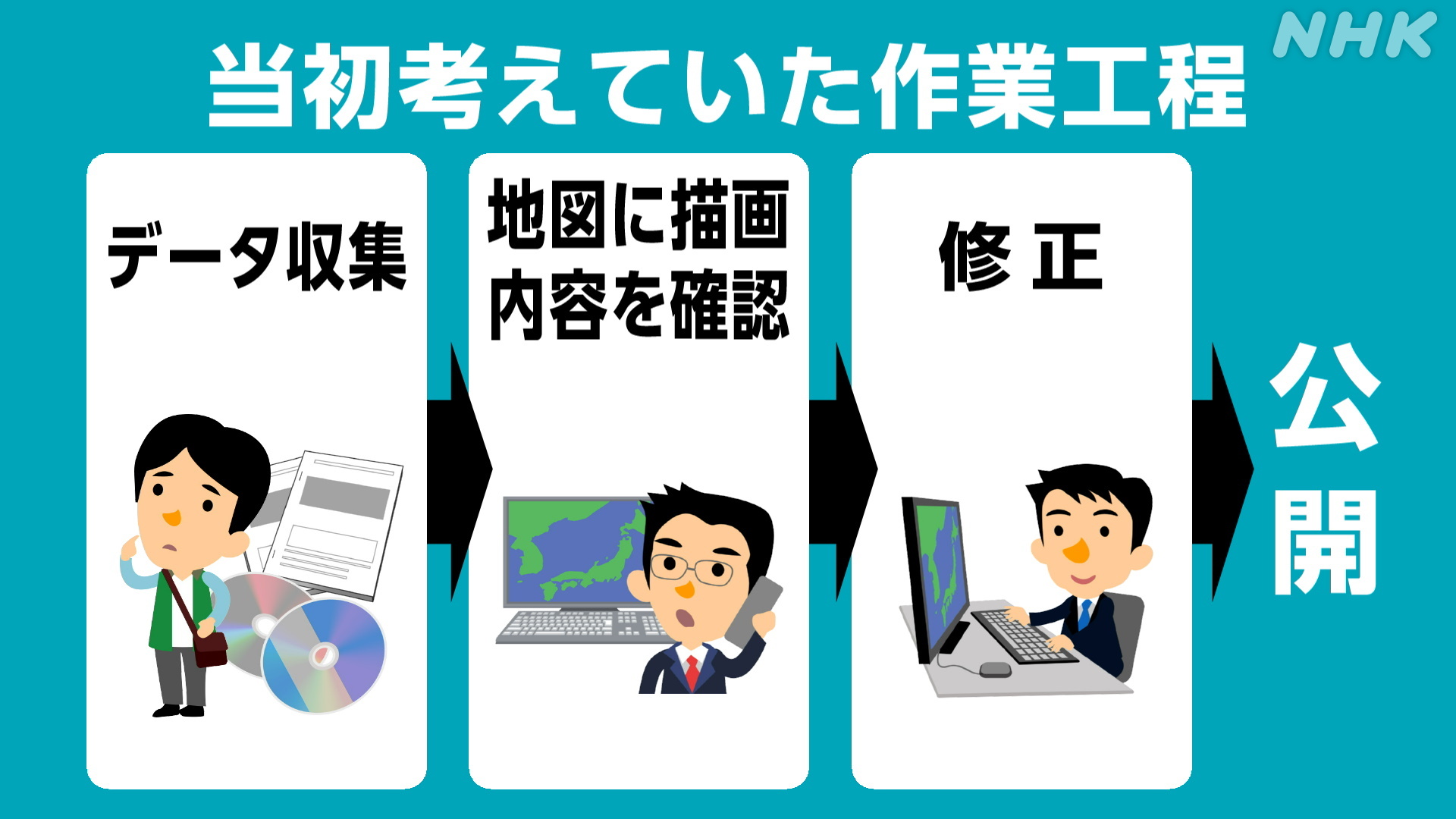
まずは、データの収集です。
国土交通省の全国にある地方整備局と、都道府県の河川部局に連絡。「公表している洪水浸水想定区域図(想定最大規模)のデジタルデータを全て下さい」と依頼しました。
「全て」としたのは、取材の中で、従来まで法律で作成が義務付けられていた「洪水予報河川」や「水位周知河川」以外でも、独自に浸水想定区域図を作っているケースがあることがわかったからです(名称は「水害リスク図」や「浸水予測図」など自治体によって異なる)。1つでも多くの情報を集めるために「全て」としました。

既に洪水浸水想定区域図をオープンデータにして、誰でもダウンロード可能な形で公開している県の場合は簡単でしたが、多くは、情報開示請求や情報提供依頼の文書を送付するなどの対応が必要になりました。
普段はデジタルデータを扱わない職員も多いため「シェープファイルを提供して欲しい」と伝えてもなかなか理解してもらえないケースや、提供されても必要なファイルが揃っていないケースもありました(GISソフトで描画するには、.shp/.shx/.prj/.dbfのファイルがセットで必要なところを.shpだけを抽出して提供されたために描画できず再度提供を依頼することも)。
自治体では紙やPDFのデータしか持っていないため、シミュレーションを実施したコンサルタント会社に問い合わせてもらい、会社から直接データを提供してもらうこともありました。
やりとりに時間がかかり、最終的には直接訪問して提供してもらったところもあります。
こうして集まったデータは実に34テラバイト(!)にのぼりました。
データの入ったHDDを貸与してもらいコピーして返却する方法が最も多かったのですが、数テラバイトのデータ量がある県では、コピーだけで1週間かかることもありました。

今回は3台のパソコンをフル稼働しましたが、常にHDDが接続されて見たことがない状態に…。
中には、数箱の段ボール箱にHDDを詰め込んで送られてきたケースもありました。

もちろん全国の河川のデ―タを集めるので、それなりにデータ量は多くなると思っていましたが、想像を超えていました。
私たちは「洪水浸水想定区域(想定最大)」のデータ提供を依頼しましたが、実際には関係の無いデータもまとめて届いたからです。例えば、「洪水浸水想定区域(計画規模)」や「家屋倒壊等氾濫想定区域」、「破堤点ごとの浸水想定」のファイルなどです。こうしたデータが混ざっていたことが桁違いのデータ量になった一因でした。

データ収集をする中で地図に載せる上で不要なデータが大量に含まれることがわかった以上、必要なファイルを抽出する必要が出てきました。つまり、当初予定していたフローに加えて、上の図のように「取捨選択」という工程が加わったことになります。
ただ、34テラバイトにのぼる膨大なデータを、1つ1つ手作業で確認していくのは不可能です。そこでプログラムを組んで必要なファイルを自動で抽出することにしました。(ここからは専門的な話なので「自治体の担当者とともに確認作業」まで飛ばして頂いてOKです)
データはバラバラ…このままでは使えない
ところが集めたデータを詳しく見ていくと、自動で必要なファイルを抽出することが簡単ではないことが見えてきました。
必要なファイルを自動で抽出するには、「何の」情報を「どの」ファイルから取り出すのか指示する必要がありますが、フォルダの構造やデ―タのフォーマットが都道府県によってバラバラだったのです。
実は、国は「浸水想定区域図データ電子化ガイドライン」を発表して、洪水浸水想定区域図を作成した時のフォルダ構造やデータのフォーマットを具体的に示しています。
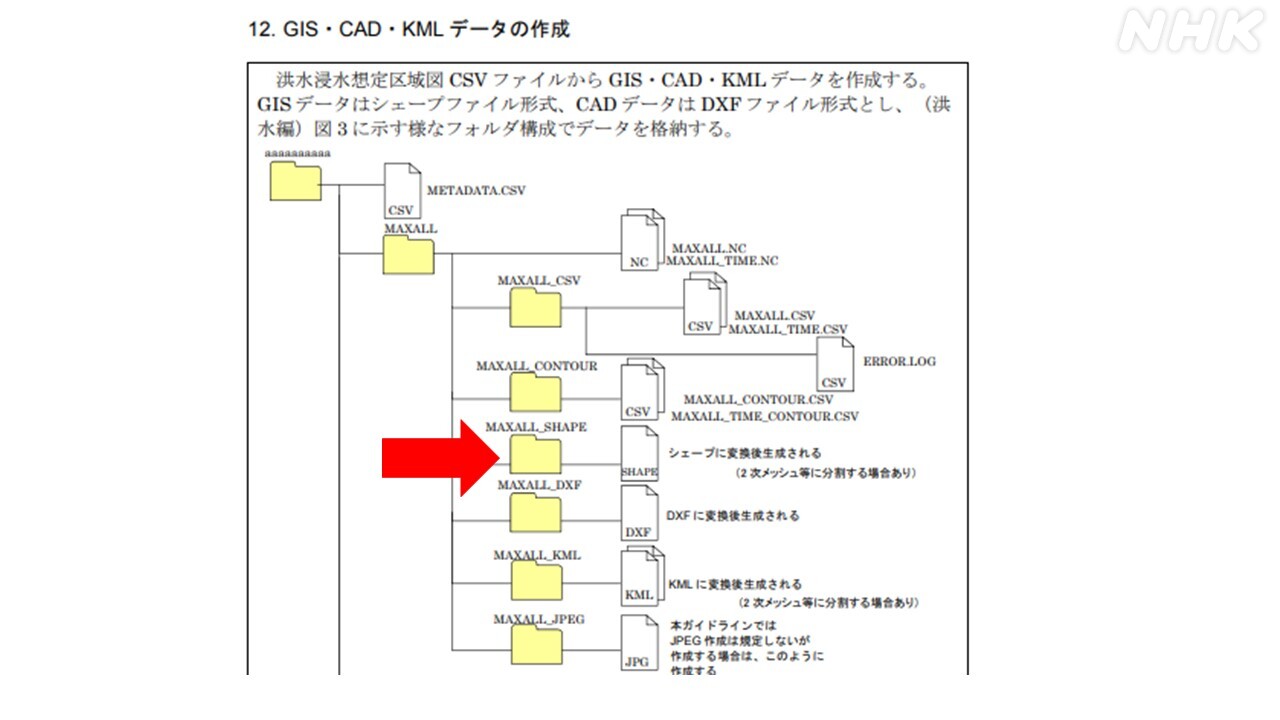
それに則れば、今回は、提供されたフォルダのうち、上の図の赤い矢印で示したフォルダ内にあるファイルだけをピックアップするよう指示すれば必要なものがそろうはずです。
ところが、提供されたフォルダを開いてみると、都道府県ごとにフォルダの構造はバラバラ。ファイルの名前も
「○○さん整理後」
「←これです!」
「※最新」
などといった記述になっていました。作業の過程で担当者が見てわかりやすいように付けたものが、そのまま残っていたものと思われます。
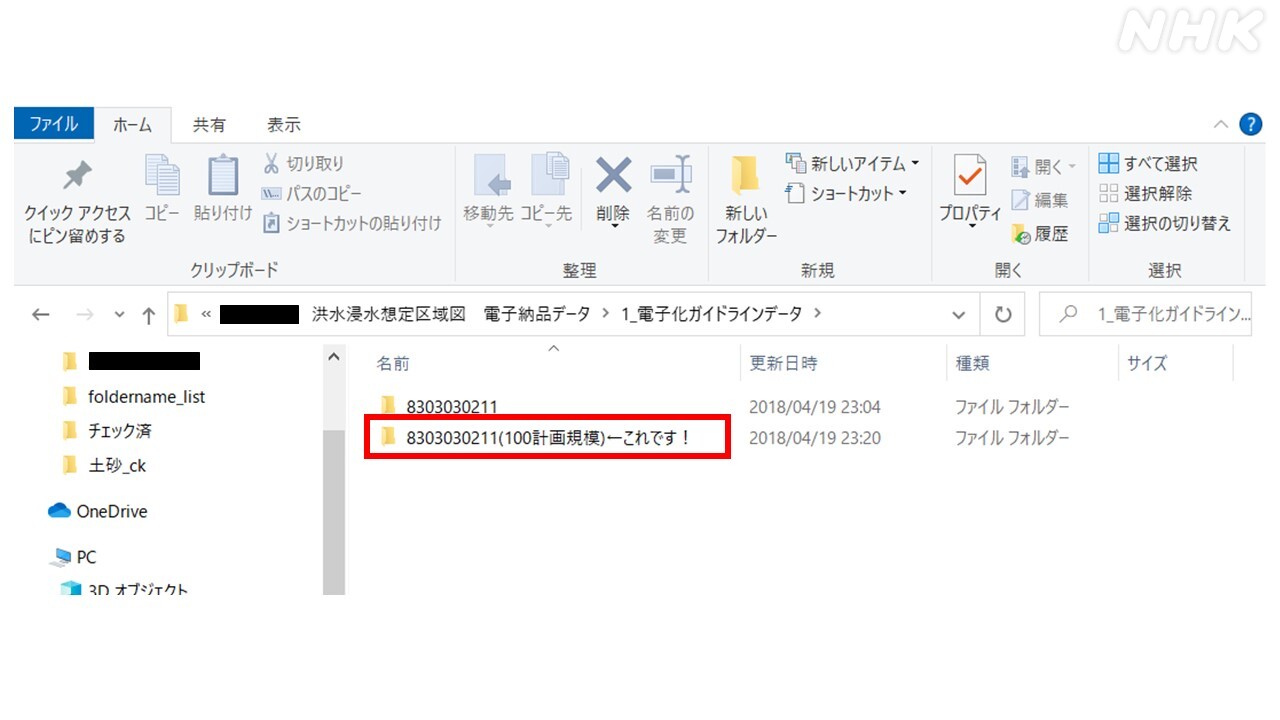
これではプログラムを組もうにも、どこにあるファイルを抽出すれば良いか指示を出せません。
さらに大変なことに、仮に必要なファイルが格納されているフォルダを特定できたとしても、今度は格納されているシェープファイル自体にも課題があることがわかりました。
シェープファイルには「位置情報」や「浸水深」だけでなく、「標高」「水位」「行番号」など様々なデータがくっついています。今回はこのうちの「浸水深」の値が並ぶ「カラム」(データを表形式で表示した時に縦方向に並んだデータの列)を選び、地図に描画する必要があります。もし間違って「標高」のデータを選んでしまえば、正しく描画されません。
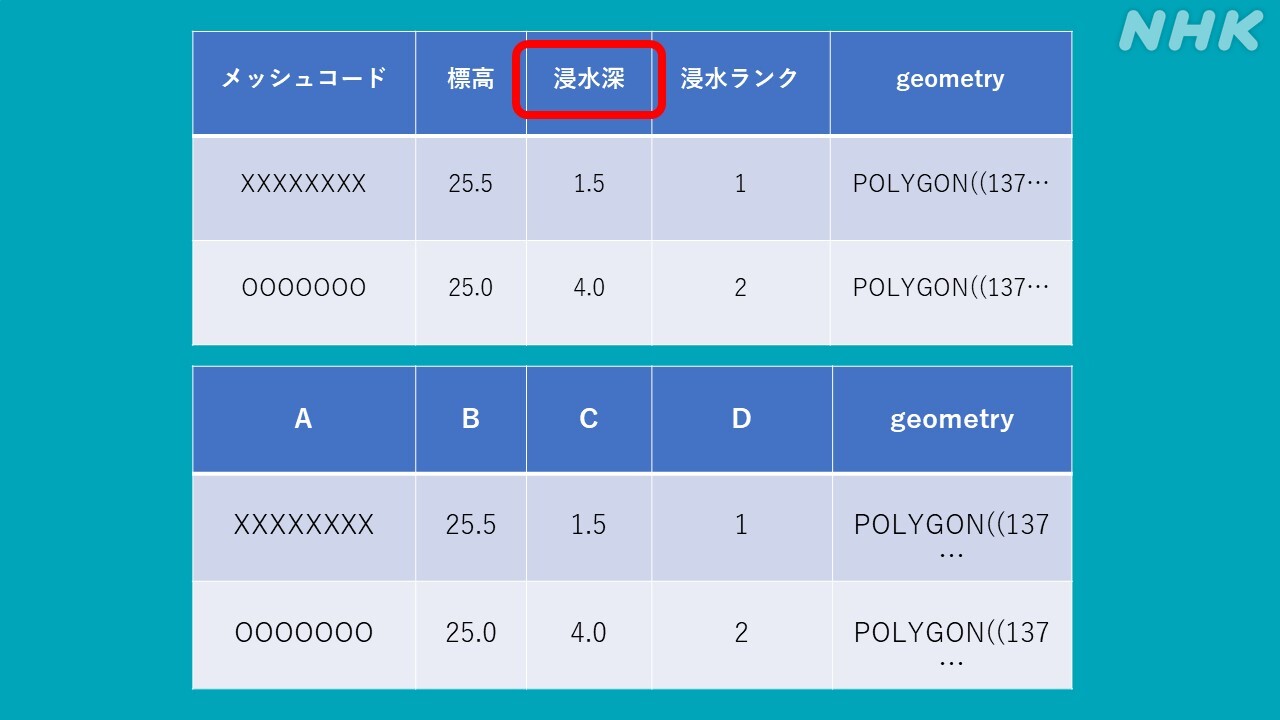
ガイドラインに則っている自治体の場合は、シェープファイルを開いた時に、図の上側の表のように、どこの列に浸水深のデータが記載されているかわかります。ところが、下側の表ように、どの列が浸水深なのか判別できないものがたくさん出てきたのです。
どうやって取捨選択したか?
こうなると手間はかかりますが、人の目を入れながら探し出していくしかありませんでした。
そこで、私たちは①対象となるファイルを特定、②浸水深のデータを抽出する、という2つの工程を経て、扱いやすい統一的なフォーマットに変換する作業を行うことにしました。
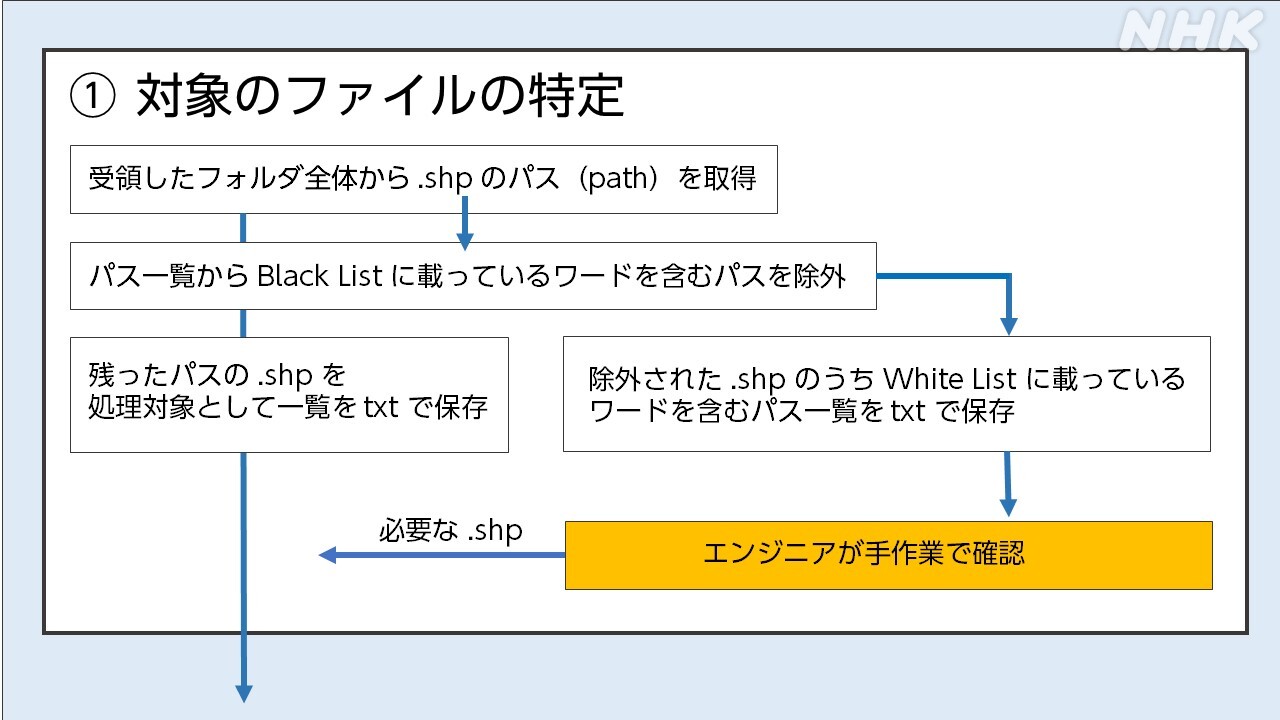
まず、①必要なファイルを特定する作業です。
今回必要なのは「GISソフトで扱えるシェープ形式の洪水浸水想定区域図(想定最大規模)」なので、収集した大量のデータの中からシェープファイルのパスだけを選びます。
パスというのはファイルの所在を示す文字列で、ディレクトリ名を並べて示した下のようなものです。
この時点で、シェープファイルの数はなんと1358万3715(!)。
ここから「不要なもの」を除外します。
必要なのは「洪水浸水想定区域図(想定最大規模)」。よって、それ以外の「洪水浸水想定区域図(計画規模)」や「家屋倒壊等氾濫想定区域」、「破堤点ごとの浸水想定区域」などは不要です。
このため「計画規模」や「家屋倒壊」など「不要なファイルと判断する単語」を40個指定し(Black List)、それらの単語を含むパスを除外。残ったファイルは「必要なファイル」として次の工程に進めることにしました。
また、一度、Black Listに基づいて除外したファイルも、本当に不要かを改めて確認しました。例えば、フォルダ名が「計画規模と想定最大規模」だった場合には、「計画規模」という単語を含むためにBlack Listで不要と判断されますが、実際には想定最大規模のファイルが格納されている可能性があるからです。
そこで、今度は「想定最大」や「souteisaidai」など「必要かもしれないファイルと判断する単語」を12個指定し(White List)、それらの単語を含むパスを抽出。あとは、ひとつひとつ人間が中身を確認することにしました。この作業だけで数週間かかりましたが、必要なシェープファイルが見つかったケースもありました。
ここまでの処理で当初1300万あったシェープファイルを100分の1の16万まで絞り込みました。
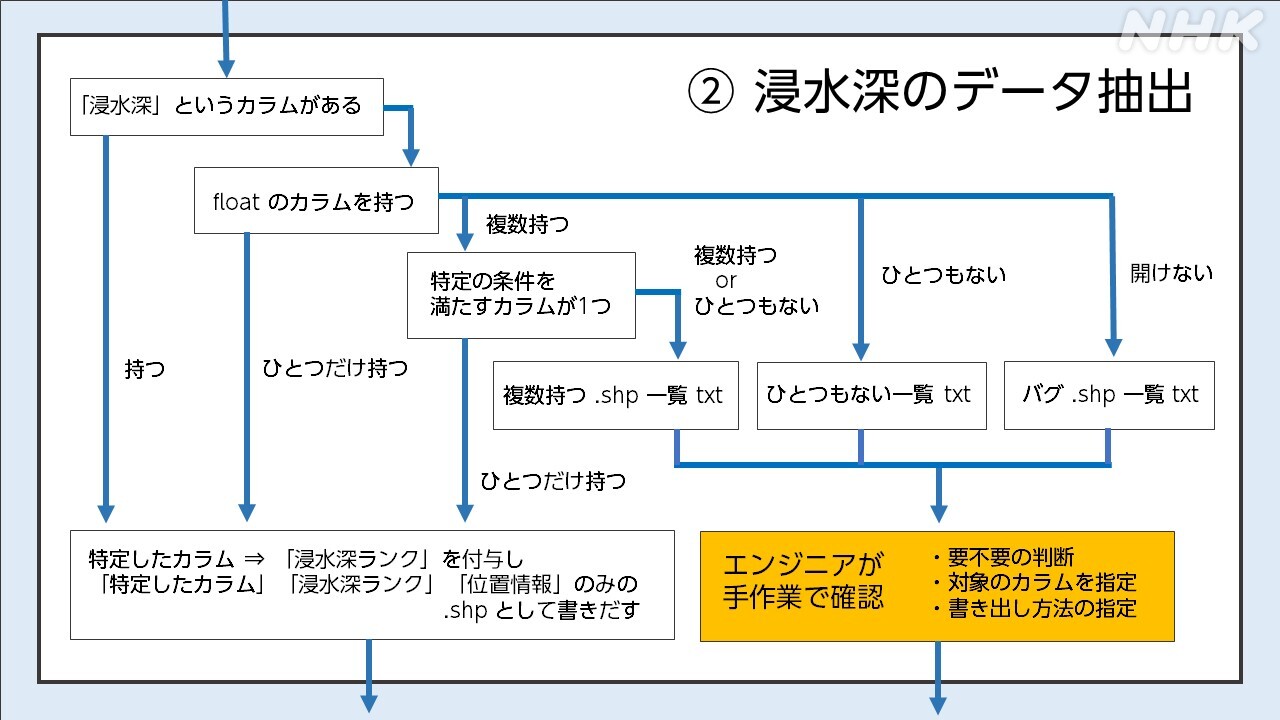
次に、②浸水深のデータを抽出する作業です。
プログラムで16万あるシェープファイルのカラム(データを表形式で表示した時に縦方向に並んだデータの列)を確認。「浸水深」という記述が確認できたものは「必要なファイル」として次の工程に進めます。
ファイルに「浸水深」というカラムが見当たらない場合はカラムの数字に注目。通常、シミュレーションに基づく浸水深の値は整数値にはならず小数点を含みます。なので「小数点を含む値が入るカラムが1つしかない場合」は、そのカラムを浸水深だと自動的に判断するプログラムを組みました。
一方、「小数点を全く含まず整数値しかないファイル」や「小数点を含むカラムが複数あるファイル」は、これまたファイルを1つずつ開いて、どのカラムを浸水深とするのかを人の目で確認して特定しました。この工程には2~3か月かかりました。
最後にデータを少しでも軽くするため、浸水深の値をもとに6段階の浸水深ランク(※)に振り分け、それ以外の使わないデータを削除。位置情報と浸水深ランクの情報だけを持つ軽量化されたシェープファイルを作成しました。
必要なデータの取捨選択と地図に載せるための統一的なフォーマットにするまでに半年。ただ、この工程で当初は34テラバイトあったデータを2.8テラバイトまで小さくすることができたのです。
----------
(※)6段階の浸水深ランク:国土交通省は浸水の深さに応じて以下のように6段階のランク付けをしています。1:0.0~0.5m未満、2:0.5~3.0m未満、3:3.0~5.0m未満、4:5.0~10.0m未満、5:10.0~20.0m未満、6:20.0m以上自治体の担当者とともに確認作業
こうして、半年以上かかって、ようやく地図に載せることができた「洪水浸水想定区域図」。複数の河川の浸水範囲が重複する場合には最も深い浸水深を採用して描画しました。
ただ、これで終わりではありません。
描画された地図に間違いが無いか確認する必要がありました。提供を受けたデジタルデータをそのまま描画しているので問題は無いはず・・・と思っていましたが、想像以上に大変でした。
確認は国と都道府県の担当者に協力して頂きました。確認用のサイトを作ってIDとパスワードを担当者に提供。地図の確認を依頼しました。そして指摘を受けた場所については1つ1つ解決していきました。
最も多かったのは「〇〇川の浸水想定区域が載っていない」といった指摘です。
この指摘を頂くたびにデータの有無を確認する必要がありました。
ところが、それが思った以上に大変でした。
例えば「A川の浸水想定区域が載っていない」という指摘があった場合は、提供されたデータの中から「A川」と名前のついたデータを探せば良い訳ですが、フォルダ名に河川名が入っておらず「その1」「その2」などと記載されたフォルダが数十あるケースや、ファイルに「〇〇川水系」とだけしか記載がされていないため、特定が難しいケースが相次いだのです。
そうした場合には可能性のあるシェープファイルを片っ端からGISソフトで描画し(場合によっては数百のファイルを描画することも)、該当するものを特定しなければなりませんでした。
中には「B川」というシェープファイルを描画したら、そこに「A川」が含まれていたとうケースもありました。
確認の結果、元データ自体が欠損していたり、データの提供を頂いた時点で漏れていたりするケースもあったりして、その場合は自治体などに改めてデータを提供して頂いて修正を進めました。ただ、上記のように、河川ごとにフォルダがわかれていないため、自治体もどこにデータがあるのかわからず、探すのに時間がかかるケースもありました。
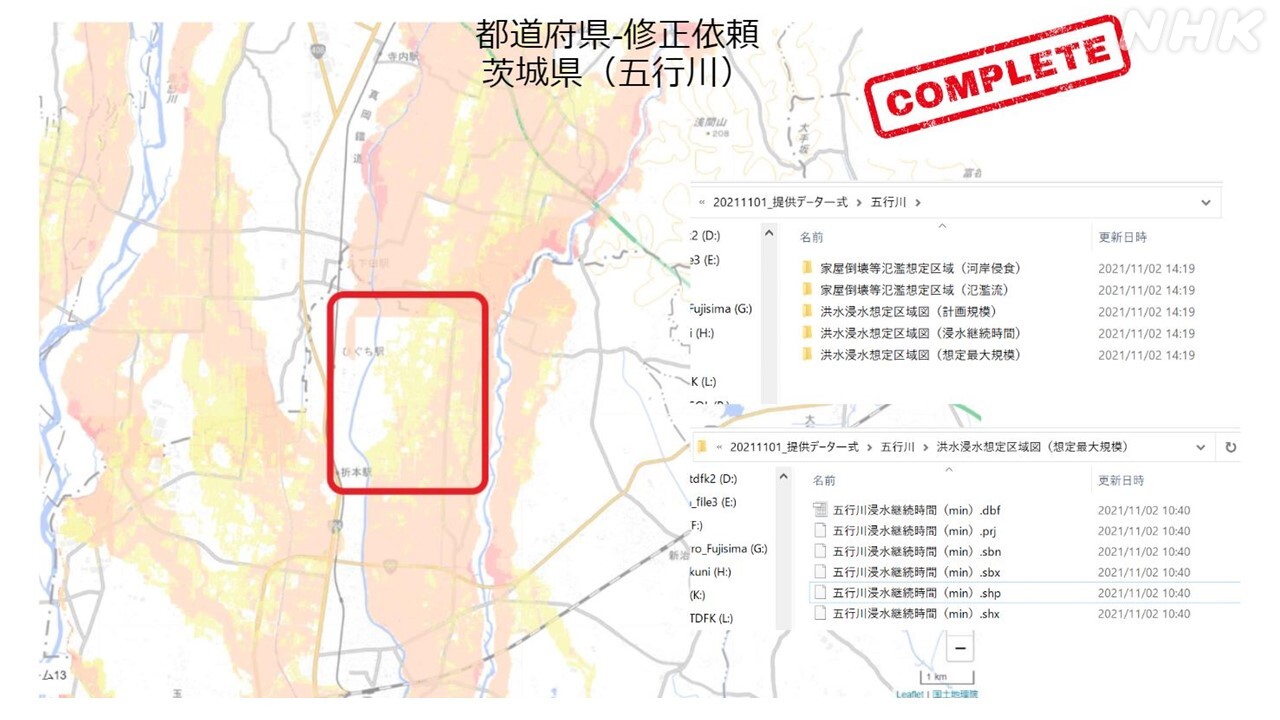
上のようなケースもありました。
この川では浸水域の一部が矩形に抜けていました。そこで、この川の名前のフォルダを見ると確かに「洪水浸水想定区域図(想定最大規模)」というフォルダがあるので、本来なら描画されているはずです。ところが、フォルダを開いて確認すると、入っていたのは「浸水継続時間」という別のファイル。この川については改めてデータ提供をお願いして解決しました。
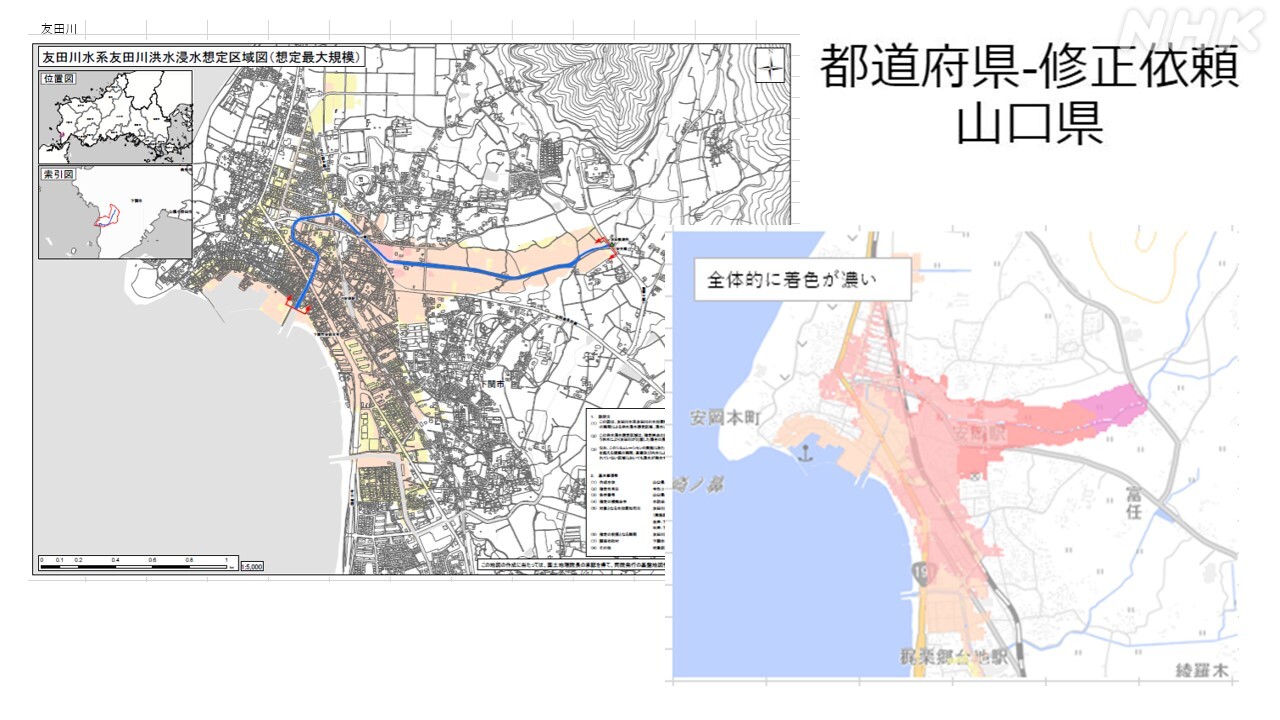
「浸水深ランクの色が違っている」という指摘もありました。
これはシェープファイルのどのカラムを浸水深としてピックアップするのかの指定が誤っていたことが原因でした。ただ、カラムを見ただけでは数字とアルファベットの意味がわからないため、自治体に確認。「5Hmax」の値を描画することで解決しました。
河道内の着色を削除する依頼も多数ありました。ただ、今回NHKでは元データに触らないようにしたため、河道内が着色されていないデータの再提供を依頼しました。ところが、自治体がそうしたデータを持っていなかったために、注釈を付けて公開したケースもありました。
こうした確認作業におよそ2か月の時間がかかりましたが、何とか5月末に公開にこぎつけました。
「最終成果物は紙」という文化
今回の取り組みを通じて、都道府県からは「近年、水害が相次ぐ中で水害リスクについての問い合わせが増えており、多くの人にリスクを認識してもらう上で大変ありがたい」とか「県として住民に周知していきたい」といった声も頂きました。また、デジタルデータをオープン化して誰でも活用できるようにする動きも広がりつつあります。
ただ、現状では、時間とお金(税金)をかけて作った「洪水浸水想定区域図」のデジタルデータの管理に課題があります。
ある担当者が発した「最終成果物は紙なんです」という言葉が印象に残っています。問題の根底にある考えを端的に言い表しています。
これまでは紙に印刷して配ることがゴール。途中経過のデジタルデータは重要視されてきませんでした。そのため、取材の中では、コンサルタント会社に浸水シミュレーションを委託しても「納品されるのはPDFだけ」という自治体がありました。デジタルデータを書き出して手を加えたものをPDFなどで公開しているために「公開しているPDFと一致するデジタルデータがそもそも存在しない」という自治体もありました。
自治体とコンサルタント会社のやりとりの中でできたフォルダがそのまま残っていたり、データの扱いがガイドラインに則っていなくても自治体から指導がなかったりすることで、バラバラのフォルダ構造やファイル形式が生まれてしまいました。
それが結果的にリスク情報を「誰でも」「どこでも」「簡単に」確認できる状況を阻んでいます。
日本の災害リスクは水害だけではありません。地震や津波もあります。様々なリスクを同時に考える必要が出てくる中では紙では限界があります(もちろん紙のメリットもありますが)。デジタルデータの重要性を改めて認識する必要があります。
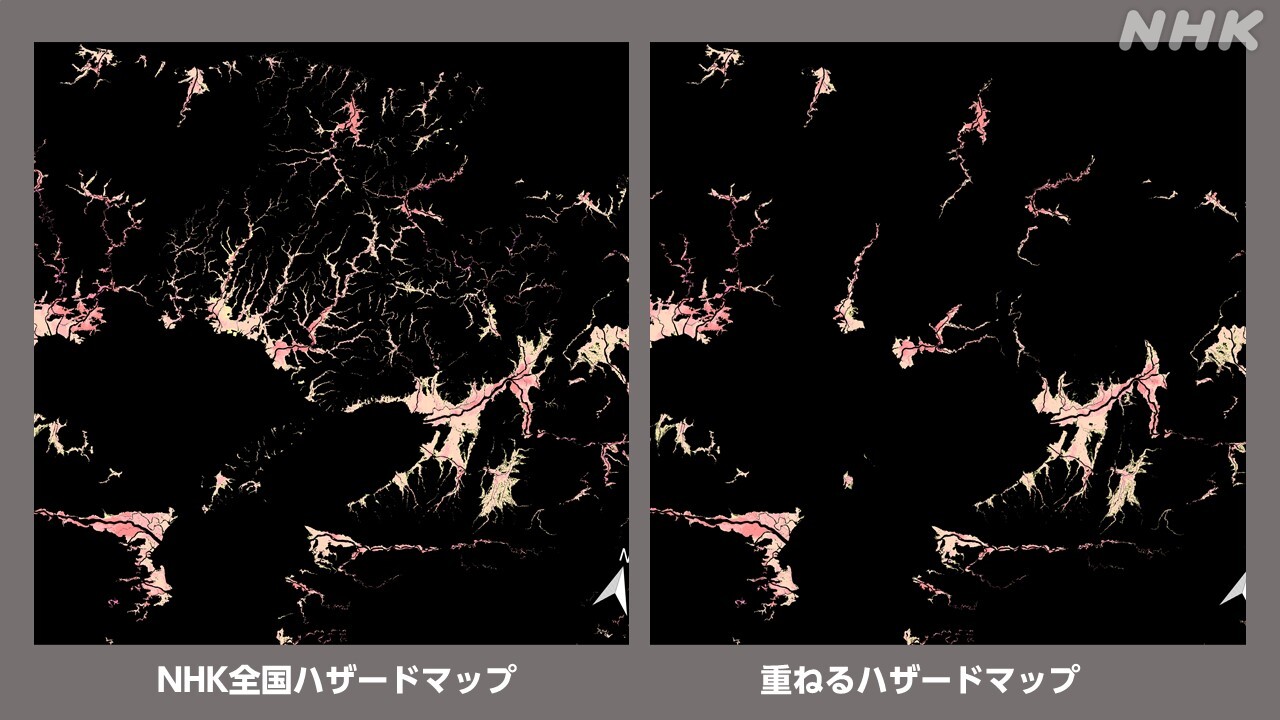
最終的にNHKの「全国ハザードマップ」には約5000の河川が掲載されています(6/10現在)。国土交通省の重ねるハザードマップの2倍の河川です。「少しでも多くの河川を掲載したい」という思いはある程度達成できたと思います。
ただ、データ収集を終えてから公表までの間にも、河川の浸水想定は次々に発表されていて、4月末時点で見ると、およそ1000河川の掲載が間に合っていません。また、雨水の排水が追いつかなくなって浸水被害が出る「内水氾濫」もカバーしていません。今後の更新課題です。
まずは、全国ハザードマップで自宅や職場、学校、実家などがリスクを抱えていないか確認して頂きたいですが、仮にハザードマップでは色がついていなくても「大丈夫だ」とは思わないでください。お住まいの市区町村が出すハザードマップ、都道府県が公表する「浸水想定区域図」を確認して下さい。浸水想定区域図の作成が追いついていないこともあるので、川の近くにお住まいの方、堤防や橋よりも低い場所にお住まいの方は、浸水リスクがあると考えて対応して下さい。
(ネットワーク報道部 記者 藤島新也/人事局 データアナリスト 浅野将/コンテンツセンター ディレクター 大石寛人)

あわせて読みたい
-

浸水リスク地域で増える住宅 一体何が…
NHKは全国の浸水想定区域(ハザードマップ)のデータと国勢調査のデータを使い、建物の1階が水没するリスクがある場所の人口変化を調査。見えてきたのは洪水の危険性があるエリアに次々に住宅が増加している実態。首都圏でも…。
-

「浸水域に約4700万人居住」の衝撃
大雨や台風による洪水リスク。国や都道府県が「浸水想定区域図」としてハザードマップなどで公表しています。最近、この浸水想定区域図が大きく変わっていることをご存じですか?分析すると、浸水エリアで人口が増えている実態が。
-

83人の死から見えたものは
2020年7月の熊本県を中心とした豪雨災害。犠牲になった83人の「被災場所」「経緯」を詳細に分析しました。「2階に避難しても助からない」ケースも。課題や教訓は。
-

川の氾濫による洪水 警戒のポイントは?
NHK防災これだけは。川の氾濫の警戒点と避難のポイントです。川の特徴を知り、あらかじめいつ避難するかタイミングを決めておくことが大切です。
-

「まさかここで」の土砂災害はどこで?…全国調査しました
土砂災害の多くは土砂災害警戒区域などリスクが示されているところで起きますが、実は地図やハザードマップで「危険性が示されていない」場所でも。突然の土砂災害から身を守るためにどのようなポイントに注意すればいいのか。